Capability
Can the agent solve the specific tasks (e.g., Coding, Math) it was designed for?
Stability
Does it perform consistently across multiple runs? (e.g., success rate over 10 trials)
Regression Detection
Does behavior change when you tweak the system prompt or switch from
qwen2.5-max to qwen3-max?Overview
To address the complexity of evaluating agents, AgentScope employs a framework decomposes the evaluation into several key components:- Benchmark is responsible for defining “Task” (what to evaluate) and “Metric” (how to judge it). It is the static standard against which agents are measured.
- Solution acts as an Adapter Pattern. Since every Agent might have unique input schemas or memory structures, the framework cannot call them directly. The Solution module standardizes this interaction.
- Evaluator orchestrates the workflow. It manages resources, concurrency, and persistence. It serves as the bridge connecting the Benchmark to the Solution.
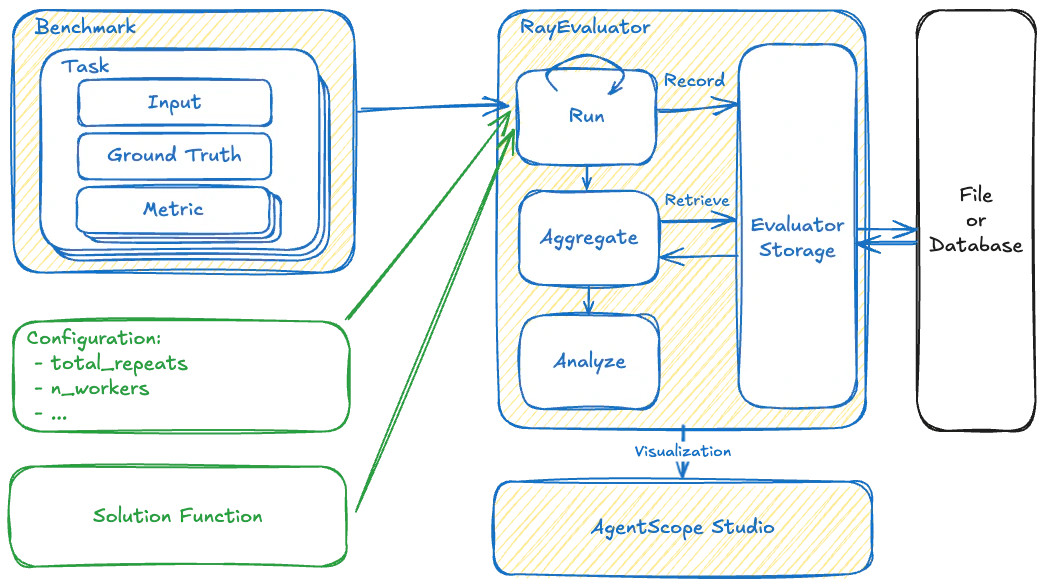
The Evaluation Pipeline
Let’s build a complete “Math Capability Evaluation” pipeline to demonstrate how to use the AgentScope evaluation module.Building Metric
In AgentScope, we useMetric to define how to grade. A Metric accepts a SolutionOutput (the agent’s answer) and returns a MetricResult.
Constructing Benchmark
A Benchmark is not just a list of questions; it organizes multipleTasks for systematic evaluation.
Crucially, the Task is the self-contained unit of evaluation that carries all information and Metric for the agent to execute and evaluate (e.g., input/query and its ground truth)
Adapting the Agent
TheSolution is a function that acts as an Adapter. It takes a standardized Task as input and produces a standardized SolutionOutput.
This isolation ensures that you can swap agents without changing the benchmark, or swap benchmarks without rewriting the agent.
We need to define the logic for running agents and retrieving the execution result and trajectory in the Solution.
Running the Evaluator
Evaluators manage the evaluation process. They automatically iterate through tasks in the benchmark and feed each task into a solution-generation function.Advanced Metrics: Integrating OpenJudge
While simple string matching (like theCheckEqual metric) works well for deterministic tasks, you can also implement MetricBase to use a stronger LLM to score subjective qualities such as tone, helpfulness, or safety, which are impossible to measure with simple code.
To achieve this without building evaluation prompts from scratch, you can integrate OpenJudge. By connecting OpenJudge to AgentScope, you gain immediate access to 50+ battle-tested, professional-grade graders directly within the AgentScope MetricBase architecture.
Building OpenJudgeMetric
To make OpenJudge compatible with AgentScope, we create an adapter class. This class inherits fromMetricBase and translates AgentScope’s SolutionOutput into the payload OpenJudge expects.
Constructing Benchmark with OpenJudge Graders
Since theTask is the self-contained unit of evaluation that carries all information and metrics for the agent to execute and evaluate, we need to define a Mapper when constructing it. The mapper tells the wrapper how to extract the query, response, and context from your specific task data to feed into the OpenJudge Grader.
QABenchmark can be run seamlessly using the exact same GeneralEvaluator or RayEvaluator shown in the pipeline overview, standardizing your subjective assessments without changing the orchestrator logic.